Redes neuronales para dimensionar Oficina de servicios al ciudadano

En este proyecto hemos utilizado redes neuronales para predecir la demanda de trámites con el fin de encontrar la forma óptima de dimensionar una oficina de servicios al ciudadano.
Dimensionar una oficina de servicios con redes neuronales
Cuando nos acercamos a una oficina de atención al público, siempre deseamos esperar poco para ser atendidos. Ese tiempo de espera dependerá, entre otras cosas, de la cantidad de mesas disponibles en la oficina y será menor cuantas más mesas haya.
Desde la perspectiva del administrador de la oficina, sin embargo, aumentar el número de mesas no siempre es una opción, puesto que esto implica una mayor inversión inicial y costes de mantenimiento más elevados.
Nuestro cliente, el ayuntamiento de una importante ciudad del área metropolitana de Barcelona, se encontraba planificando las obras de reforma de sus oficinas de atención al público y deseaban encontrar el equilibrio entre ofrecer a sus ciudadanos un servicio con bajos tiempos de espera y optimizar el uso de sus recursos. Es decir, quería saber cuál debería ser la dimensión ideal de sus oficinas.
Para encontrar dicho equilibrio hemos propuesto una solución compuesta por dos partes que, si bien son independientes, encajan perfectamente. La primera de ellas se encarga de predecir la carga de servicio. Esto es, la cantidad de horas que deberá trabajar la oficina para atender la demanda a la que está sometida. La otra, estima el tiempo de espera promedio para una cantidad de mesas y una determinada carga de servicio.
Para la predicción de la carga de servicios hemos empleado redes neuronales. En cambio, para estimar los tiempos de espera, hemos propuesto un modelo que se ajusta a las propiedades de los datos provistos por nuestro cliente.
El resultado es una herramienta basada en métodos de Inteligencia Artificial que asiste al cliente en la toma de decisiones.
Dataset
Nuestro cliente nos ha provisto de un extenso conjunto de datos que contiene el registro de las atenciones al público realizadas por los gestores de su Oficina de Atención al Ciudadano.
Los datos corresponden al período entre los años 2000 y 2019. Incluyen información de los instantes de solicitud de atención por parte del usuario, comienzo de la atención y finalización. También se detalla el tipo de trámite y el tema del mismo.
Limpieza y preparación de dataset
En la limpieza de datos hemos eliminado todos aquellos registros con errores o datos faltantes. En el proceso descubrimos que un gran porcentaje de los registros incompletos se encontraban entre los años 2000 y 2008. Por ese motivo, consideramos descartar ese período y sólo hemos trabajado con los datos entre 2009 y 2019.
Análisis Exploratorio de Datos
En primer lugar hemos estudiado el volumen de trámites por día en el período considerado. Luego, consideramos discriminar trámites con y sin cita previa y por tema de trámite. Del mismo modo, analizamos el número de atenciones por hora.
Por otra parte, también estudiamos los tiempos de espera medio y tiempos de atención. Esto lo hicimos para cada año, mes, día del año, día de la semana y hora. En este punto descubrimos que, en promedio, los tiempos de atención no varían a lo largo del día. Es decir, el tiempo de atención es constante.
Durante el análisis exploratorio consideramos que sería relevante conocer la cantidad de tiempo necesaria para atender los trámites de los usuarios. Para ello, definimos la carga de trabajo como la suma de las duraciones de las atenciones. Esta nueva magnitud, permite establecer cuántas horas de trabajo se requieren para atender una dada demanda. Al igual que en el resto de los casos, hemos estudiado distintos aspectos de esta cantidad.
Modelos Predictivos
Como vimos en la introducción nuestro proyecto está compuesto de dos partes. Para saber cómo conviene dimensionar una oficina utilizaremos redes neuronales para la predicción de los servicios y un modelo minimalista para la estimación de los tiempos de espera.
Predicción de la carga de trabajo
Una de las partes de nuestra propuesta se encarga de la predicción de la demanda por parte de los usuarios. Esto significa que, sabiendo cómo ha sido la demanda en el pasado, nuestro modelo predictivo dará un valor para la demanda en el futuro.
Dado que los datos están indexados con la fecha y hora a la que comenzó un trámite, podemos abordar la problemática como una serie temporal. Existe una gran cantidad de modelos para predecir series temporales entre los que podemos encontrar AR, MA, ARMA y ARIMA, entre otros.
Sin embargo, en los últimos años han aparecido redes neuronales capaces de predecir series temporales. Se conocen como redes neuronales recurrentes y entre las más populares están las LSTM. Este tipo de redes neuronales son capaces de extraer patrones de la serie temporal y extrapolarlos al futuro.
Es decir, como primera componente de nuestro sistema para dimensionar la oficina, utilizaremos redes neuronales recurrentes con el fin de predecir la demanda de servicios.
Tiempo de espera medio
La otra parte de nuestra propuesta se encarga de hallar el tiempo de espera medio para una dada demanda. Claramente, la demanda corresponde a la carga de trabajo predicha por la primera parte de nuestra solución. Además de esta variable, para calcular el tiempo de espera medio también debemos tener en cuenta el número de mesas disponibles y el tiempo de atención.
En nuestro análisis exploratorio hemos visto que el tiempo de atención a lo largo del día es constante. Esto simplifica nuestra propuesta ya que la carga de trabajo y el número de trámites son proporcionales y la constante de proporcionalidad es, justamente, el tiempo de atención.
Con todos estos ingredientes, diseñamos un modelo ad-hoc que: dada una determinada carga de trabajo atendida por un dado número de mesas, que atienden a cada usuario en un tiempo de atención, calcula el tiempo de espera medio de cada usuario.
En este punto debemos notar que, el parámetro que estamos buscando para hacer el redimensionamiento es justamente el número de mesas. Es decir, queremos ver cuál es el número de mesas óptimo para que los usuarios tengan tiempos de espera satisfactorios. Esto lo podremos ver al variar el número de mesas en nuestro modelo. Es de esperar que a medida que aumentemos el número de mesas, disminuya el tiempo de espera.
En resumen, lo que haremos es buscar el número de mesas tal que, dada una carga de trabajo y tiempo de atención, equilibre tiempos de espera pequeños con la menor cantidad de mesas en la oficina.
Resultados
Predicción de la carga de trabajo
En la siguiente figura se puede ver el resultado de la predicción de la red neuronal. En azul se muestran los datos reales, en cambio en anaranjado, la predicción. Como podemos observar, los datos reales son significativamente más ruidosos que la predicción de la red neuronal. Sin embargo, el modelo es capaz de capturar correctamente el comportamiento intrínseco de la serie temporal.
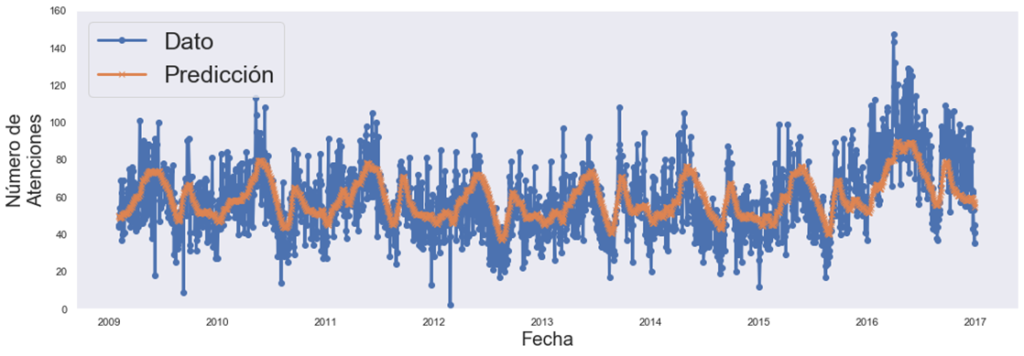
Comparativa de los datos reales con la predicción del modelo basado en redes neuronales LSTM.
En la siguiente figura podemos ver cómo el modelo extrapola la serie temporal más allá del rango de los datos originales (año 2020). En este caso hemos suavizado la curva de los datos para facilitar la interpretación del gráfico.

Predicción del modelo fuera del intervalo rango original de los datos.
Tiempos de Espera Medio
Distribución de tiempos de espera
Una vez que obtuvimos la predicción de carga de trabajo, utilizamos los valores como entrada para la segunda parte de nuestra solución. En la siguiente figura, utilizamos diagramas de caja (box plots) para ver la distribución de tiempos de espera medio obtenidos para distinto número de mesas.

Distribución de tiempos de espera por número de mesa, representados por diagramas de caja.
A medida que se aumenta el número de mesas, los tiempos de espera son cada vez menores y están menos dispersos respecto de su valor medio.
Valores umbral
A partir de la anterior figura es posible valorar cuál es el número de mesas óptimo para un dado tiempo de espera. Por ejemplo, si consideramos que 20 minutos es un tiempo de espera razonable, trazando una línea horizontal podremos saber qué porcentaje de los usuarios esperará al menos esa cantidad de tiempo. Esto se muestra en la siguiente figura:
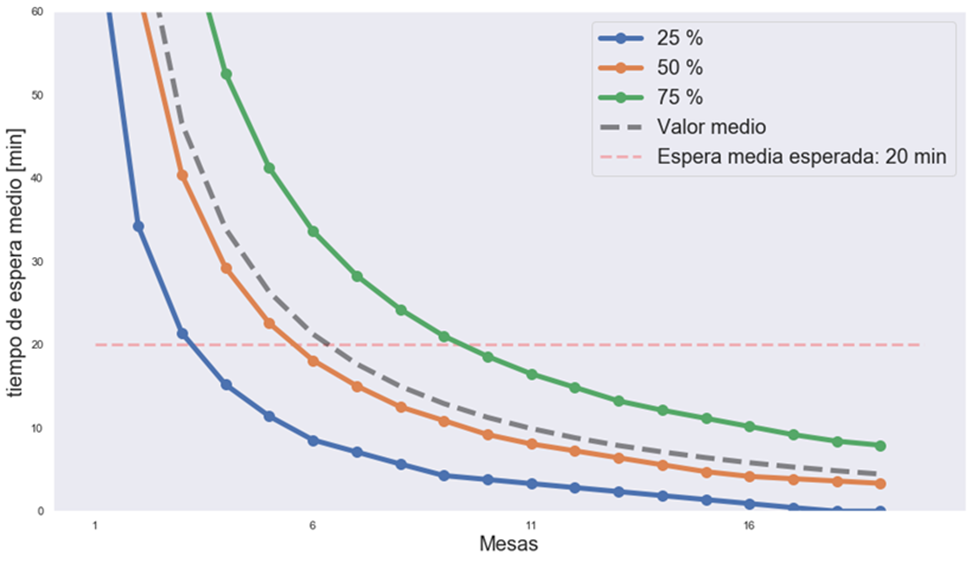
Estas curvas nos muestran el porcentaje de usuarios que esperará menos de 20 minutos en función del número de mesas en la oficina.
En esta figura, las líneas azul y verde corresponden a los bordes inferior y superior de las cajas de la figura anterior. La línea anaranjada a la línea central de dichas cajas y la línea cortada al valor medio.
En la figura se puede ver que, con una mesa, los tiempos de espera son muy grandes. A medida que aumentamos el número de mesas, observamos que la línea azul cruza la línea roja cortada cuando hay 3 mesas disponibles. Esto significa que, si la oficina dispone de 3 mesas, el 25% de los tiempos de espera es menor a 20 minutos, en cambio el 75% de los tiempos de espera es mayor a 20 minutos.
Si continuamos aumentando el número de mesas hasta 6, la línea anaranjada cruza la línea roja cortada. Esto significa que el 50% de los tiempos de espera es menor a 20 minutos. Finalmente, al llegar a 10 mesas, vemos que la línea verde cruza a la línea roja cortada. Esto implica que, si en la oficina hay 10 mesas disponibles, el 75% de los tiempos de espera es menor a 20 minutos.
Validación de resultados
En el conjunto de datos que nos proveyó nuestro cliente, se encontraba detallado el número de mesas que atendieron un determinado día. Esta información resultó sumamente útil para efectuar una validación de nuestros resultados.
Para los días donde se atendió con sólo una mesa, graficamos el tiempo de espera medio a lo largo del día y lo contrastamos con la predicción de nuestro modelo (panel superior izquierdo de la siguiente figura). Tal como podemos observar, la semejanza de ambas curvas es grande.

Comparación entre la predicción del modelo de tiempos de espera y los datos reales para 1, 7, 10 y 13 mesas (ver títulos de cada gráfico).
Hemos repetido el proceso para los casos donde se atendió con 7, 10 y 13 mesas, presentadas en los paneles superior derecho, inferior izquierdo e inferior derecho, respectivamente. En todos los casos nuestro modelo se ajusta correctamente a los datos reales lo que nos asegura que las predicciones a futuro serán satisfactorias.
Conclusiones
El objetivo del presente proyecto fue encontrar la forma óptima de dimensionar una oficina de atención al ciudadano prediciendo la demanda de servicios, para lo cual utilizamos redes neuronales, y el tiempo de espera, para lo cual diseñamos un algoritmo.
Hemos propuesto un sistema que es capaz de predecir la carga de trabajo que tendrá una oficina de atención al ciudadano. Este sistema también es capaz de calcular tiempos de espera según el número de mesas disponibles para atención, el tiempo de atención para gestionar los trámites y el número de usuarios que llegan por hora.
Otra característica relevante de nuestra solución es su naturaleza modular. Es decir, está compuesto por dos partes que funcionan de forma independiente. Como consecuencia, podemos utilizarla sólo para obtener predicciones de demanda o sólo para calcular tiempos de espera. Claramente, también es posible utilizarlo en conjunto.
Para la predicción de la demanda hemos utilizado redes neuronales. Esto la hace robusta y capaz de capturar comportamiento históricos complejos con un rápido entrenamiento.
Por otro lado, el modelo de estimación de tiempo de espera propuesto es minimalista y las hipótesis en las que se basa, se ajustan adecuadamente a los datos reales.
Funcionando en conjunto, nuestra solución permite a nuestro cliente cuantificar la reducción de tiempos de espera por mesa agregada.

Deja un comentario