Como crear tu ChatGPT privado

Crear un ChatGPT privado nos permite solucionar algunas de las limitaciones de los Chatbots que usan Modelos de Lenguaje GPT que comentamos en nuestro artículo Chatbots con Plataformas NLP vs. Modelos de Lenguaje GPT como, por ejemplo, el control total o la privacidad y seguridad.
Al desarrollar tu propio chatbot, tienes control total sobre su funcionamiento y personalización y puedes adaptarlo a las necesidades específicas de tu negocio o proyecto.
Además, con un ChatGPT privado, puedes garantizar la privacidad y seguridad de los datos de tus usuarios al evitar compartirlos con terceros o proveedores de servicios.
Estructura de un ChatGPT Privado
Para la creación de nuestro ChatGPT privado utilizaremos una técnica llamada Retrieval Autgmented Generation (RAG) que consiste en recuperar, desde una base de datos, segmentos de documentos parecidos a la pregunta realizada.
Estos segmentos, junto con la pregunta original y, opcionalmente el histórico de preguntas y respuestas anteriores, se pasa al Modelo de Lenguaje GPT (LLM) para que genere una respuesta en lenguaje natural.
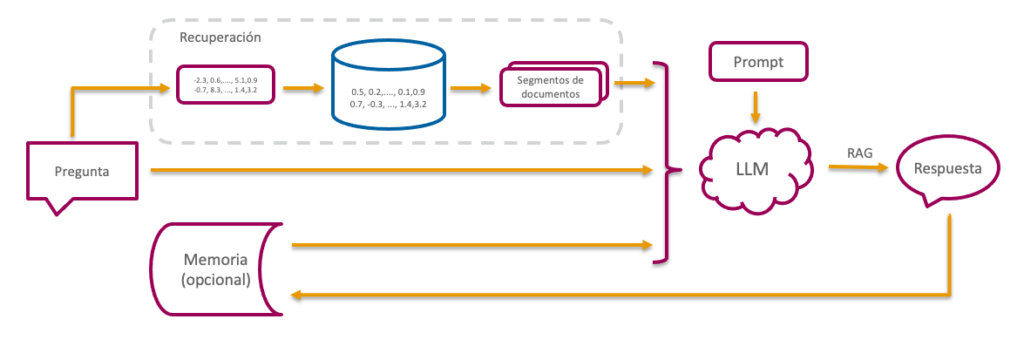
Lógicamente, para poder realizar la búsqueda en la Base de datos, es necesario haber realizado previamente una ingesta de información en dicha base de datos.
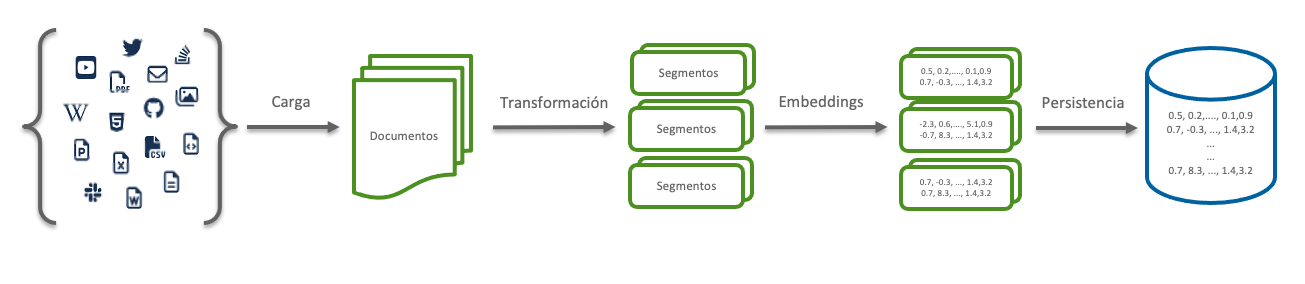
El origen de los datos puede ser muy variado, incluyendo documentos en pdf, word, hojas de cálculo, e incluso transcripciones de videos.

Una vez obtenidos los documentos, se dividen en segmentos y se codifican para poder guardarlos en la base de datos vectorial de forma que los segmentos de temática parecida permanecerán próximos.
En este artículo explicaremos cómo crear tu propio ChatGPT personalizado para que le puedas realizar preguntas sobre tus documentos,
Para la creación, usaremos como modelo una versión antigua de OpenAI (GPT 3.5 Turbo) y como base de datos vectorial ChromaDB, además, utilizaremos el framework de trabajo LangChain que facilita la integración de los diferentes componentes.
Este es un proyecto sencillo que pretende ilustrar la estructura básica de un chatbot desarrollado mediante Modelos de Lenguaje GPT.
Existen innumerables variaciones y mejoras en cada una de las secciones: modelos de embedding, almacenamiento, diseño de prompts, recuperación y modelos de lenguaje usado, pero cada una de estas mejoras dan para varios artículos y se escapan del objetivo del artículo.
Teniendo en cuenta todo esto, el artículo se estructura en las siguientes secciones:
- Configuración
- Ingesta
- Carga de documentos
- Transformación
- Embeddings (Codificación)
- Persistencia
- Recuperación y respuesta
- Definición del prompt
- Recuperación de documentos similares
- Generación de la respuesta
- Chat
- Configuración de la memoria
Creación de nuestro ChatGPT Privado
Configuración
Lo primero que deberemos hacer es importar las librerías de sistemas y recuperar desde el archivo de entorno (.env) nuestra clave de la API de OpenAI.
import os
import openai
import sys
sys.path.append('../..')
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # Leemos el fichero local .env
# Recuperación de las variables de entorno
openai.vapi_key = os.environ['OPENAI_API_KEY']
Ingesta
Como hemos comentado en la introducción, la ingesta de datos consiste en la carga de los documentos (orígenes de datos), la transformación de los mismos, la codificación y el almacenamiento.
Carga de documentos
En este caso cargaremos un documento llamado «Creacion-de-chatbots-con-IA.pdf«. Para ello, utilizaremos el método PyPDFLoader de LangChain y mostraremos información del resultado de la carga en memoria.
from langchain.document_loaders import PyPDFLoader
document = os.environ['DOCUMENT']
# Carga del documento
loader = PyPDFLoader(document)
pages = loader.load()
# Mostrar datos de la carga
print("Número de páginas del documento: ", len(pages))
page = pages[0]
print("Número de caracteres de la página: ", len(page.page_content))
print("Metadata: ", page.metadata)
print("Extracto del Contenido:" , page.page_content[0:1000])
El resultado de la carga es un iterador con tantos elementos como páginas tenga el documento. Para cada página se guarda el contenido y metadatos.

Transformación
El proceso de transformación incluye cualquier cambio que hagamos en los documentos obtenidos para mejorar su clasificación y almacenamiento. En nuestro caso simplemente realizaremos la segmentación de los documentos.
La segmentación es el proceso que divide cada una de las páginas del documento en segmentos más pequeños que facilitan la búsqueda de la pregunta y minimizan el tráfico y consumo de tokens (unidad de facturación de OpenAI).
Para facilitar la conexión de los segmentos, al dividirse, se define una parte de texto que se solapa con el siguiente segmento. De esta forma, el final de un segmento se añade al segmento siguiente facilitando el enlace de segmentos en la búsqueda.
El tamaño de los segmentos (chunk_size) y la longitud del solapamiento (chunk_overlap) se puede definir según nuestras preferencias. Es conveniente realizar varias pruebas y validar la calidad. En nuestro caso configuraremos segmentos de 1000 caracteres y solapamientos de 100.
Hay varios métodos para realizar la división en segmentos (split). En nuestro caso utilizaremos RecursiveCharacterTextSplitter que es el recomendado para texto genérico y que permite definir separadores para evitar que las frases se queden a medias al dividir el texto.
Uniéndolo todo nos queda el siguiente código.
from langchain.text_splitter import RecursiveCharacterTextSplitter
chunk_size = int(os.environ['CHUNK']) # 1000
chunk_overlap = int(os.environ['OVERLAP']) # 100
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=["\n\n", "\n", "(?<=\. )", " ", ""]
)
# Ejecutamos la segmentación de documentos
splitted_pages = text_splitter.split_documents(pages)
Una vez hemos ejecutado la división en segmentos con el método split_documents, obtendremos una lista con todos los segmentos de todas las páginas.
Como validación, podemos imprimir el número total de segmentos, así como el tamaño, los metadatos y el contenido de los cuatro primeros segmentos (los que corresponden a la primera página).
print("Número de segmentos: ", len(splitted_pages))
print("***")
for i in range(4):
print("Tamaño del segmento: ",len(splitted_pages[i].page_content))
print("Metadata: ", splitted_pages[i].metadata)
print("Contenido:" , splitted_pages[i].page_content)
print("-----------------------------------------------")
Observaremos que ha generado un total de 21 segmentos. En concreto, para la primera página ha generado cuatro segmentos, tres de ellos de tamaño aproximadamente de 1000 caracteres y un último de 545.
También podemos observar el efecto del solapamiento de los segmentos (chunk_overlap)

Embeddings (Vectorización) y persistencia
Una vez tenemos los segmentos, llega el momento de convertirlos en vectores (embedding) y guardarlos en la base de datos de vectores (ChromaDB).
Importamos las librerías necesarias, obtenemos la dirección de la base de datos y, antes de cargar la información del documento, borramos el contenido de la base de datos.
Este paso es opcional en caso de querer añadir nuevos documentos, pero obligatorio si vamos a cargar una nueva versión del documento, puesto que no existe la opción actualizar.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
persist_directory=os.environ['PERSIST_DIRECTORY']
!rm -rf $PERSIST_DIRECTORY # borramos lo que hubiera en la base de datos
La vectorización de los segmentos y la creación de los documentos la realizaremos en un sólo paso llamado al método Chroma.from_documents
A este método le debemos pasar como parámetros los segmentos, el sistema de embeddings y el directorio de la base de datos.
El formato de Embeddings que utilizaremos que debe coincidir con el modelo de Embeddings que utilizará el LLM para generar la respuesta (en nuestro caso será OpenAIEmbeddings),
Finalmente validamos que el tamaño del vector generado coincide con el número de segmentos de página que debemos cargar (21) y persistimos la base de datos en disco
# Definir el modelo de embbeddings
embedding = OpenAIEmbeddings()
# Generamos el vector codificado de los documentos a cargar
vectordb = Chroma.from_documents(
documents=splitted_pages,
embedding=embedding,
persist_directory=persist_directory
)
# Validamos el número de vectores creados
# (debe coincidir con el número de segmentos de páginas a cargar)
print(vectordb._collection.count())
# Persistimos el vector
vectordb.persist()
Generación de la respuesta

Como hemos visto en la introducción, el sistema básico de generación de una respuesta consiste en un conjunto de pasos encadenados (la salida de cada paso es la entrada del siguiente).
Estos pasos comienzan con la recuperación de los documentos que pueden contener la respuesta a la pregunta, seguidamente se pasan al Modelo de lenguaje GPT junto con un prompt para que genere la respuesta.
Langchain permite definir cadenas de pasos que incluyan en una única llamada toda la definición del proceso.
Recuperación de documentos similares
Existen diferentes formas de realizar búsquedas en las bases de datos de vectores. En nuestro caso las buscaremos en la base de datos vectordb por similitud con el método similarity_search pasando como parámetros la pregunta y el número de segmentos que queremos que retorne.
Antes de montar la cadena que responda a las preguntas vamos a validar que nuestra base de datos vectorial realiza correctamente las búsquedas en el documento que hemos cargado.
# Definimos una lista de preguntas
questions = [
"¿Qué és LLM?",
"¿Qué es SapiensXBot?",
"Cuáles son las ventajas de usar modelos de lenguaje GPT en la creación de chatbots?",
"¿y las desventajas?"
]
# Buscamos la respuesta a cada pregunta
for question in questions:
answers = vectordb.similarity_search(question,k=3)
print(question)
print(len(answers))
for answer in answers:
# para cada pregunta inprimimos las respuestas generadas
print(answer.metadata)
print(answer)
print("-------")
print("****************************************")
Efectivamente, para la primera pregunta, vemos que nos retorna los mejores tres segmentos en los que aparecen los términos buscados, y en concreto, en el primero de ellos ya se puede ver que aparece una cierta definición.

Definición del prompt
Si alguna vez has usado ChatGPT sabrás que el Prompt es el mensaje inicial que configura el entorno de la respuesta indicando al modelo GPT qué se espera de la respuesta.
La definición del prompt determina sustancialmente la calidad de la respuesta o, cuanto menos, que se ajuste a lo esperado.
En nuestro caso, el principal requerimiento que le hacemos es que responda a partir de los segmentos que va a recibir como entrada y si en esos segmentos no se encuentra la respuesta que simplemente diga que no lo sabe.
Esto es importante puesto que va a ser lo que evite que use su «conocimiento» previo para responder o que se invente una respuesta factible. En definitiva, evita las alucinaciones.
from langchain.prompts import PromptTemplate
# Build prompt
template = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know the answer, don't
try to make up an answer. Use three sentences maximum. Keep the answer as
concise as possible. Always say "Gracias por preguntar" at the end of the
answer.
{context}
Question: {question}
Helpful Answer:"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
Generación de la respuesta
Llega el momento de construir la cadena de pasos que generan la respuesta tal como hemos explicado al inicio de este punto.
la cadena se define con el método from_chain_type que necesita como parámetros:
- llm: el modelo de lenguaje GPT que utilizará
- retriever: el recuperador de la base de datos de vectores
- chain_type: el tipo de cadena
- argumentos adicionales: en nuestro caso el prompt
Como modelo utilizaremos «gpt-3.5-turbo» de OpenAI. Es un modelo antiguo, por lo que no tiene todo el conocimiento y potencia actual.
Sin embargo, como estamos interrogando nuestro documento y en el prompt ya le indicamos que no utilice su «conocimiento», es más que suficiente. Además, por el hecho de ser antiguo, el coste de utilización por parte de OpenAI es mucho más económico que las versiones actuales.
El tipo de cadena tiene que ver con la forma en que se recopilan los segmentos para generar las respuestas, y van de sistemas simples de busqueda de n mejores (stuf) a sistemas de evaluación de respuestas con todos los segmentos (map-reduce o refine).
En resumen, el siguiente paso será importar las librerías de OpenAI, definir el modelo y el tipo de cadena a utilizar y llamar a la definición de la cadena con el resto de parámetros.
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
from langchain.chains import RetrievalQA
mychain_type= "stuff"
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type=mychain_type,
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
Para realizar una pregunta, llamaremos a la cadena generada qa_chain pasando como parámetro la pregunta en cuestión.
for question in questions:
result = qa_chain({"query": question})
print(result["query"])
print(result["result"])
print('-----------')

La respuesta viene en una estructura que contiene, además de la respuesta propiamente dicha, la pregunta y los segmentos de documentos recogidos de la base de datos junto con sus metadatos.
Esto nos permitirá, aportar al usuario información adicional sobre como se ha obtenido la respuesta o enlaces a los documentos y las páginas para que pueda profundizar en los detalles.
for source in result["source_documents"]:
print(source.metadata)
print(source.page_content)
print("----")
Chat
Como se puede observar en el resultado de la cuarta pregunta, las respuestas proporcionadas hasta ahora son independientes de las preguntas realizadas anteriormente. Es decir, cuando se le pregunta por las desventajas, no asume que ser refiere al sujeto de la pregunta anterior.
Para que las repuestas tengan en consideración las preguntas anteriores debemos proporcionar memoria a las conversaciones.
Configuración de la memoria
Definimos el objeto memoria que guardará la conversación y se pasará como parámetro a la cadena de generación de la respuesta
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True,
input_key='question',
output_key='answer'
)
y redefiniremos la cadena de recuperación utilizando el método ConversationalRetrievalChain. En este caso, a modo de ejemplo, no indicaremos ningún Prompt.
from langchain.chains import ConversationalRetrievalChain
qa = ConversationalRetrievalChain.from_llm(
llm,
retriever=vectordb.as_retriever(),
memory=memory
)
Ahora, al volver a realizar las dos preguntas relacionadas podemos observar que, en la segunda pregunta, tiene en cuenta que nos referimos a las desventajas de usar modelos de Lenguaje GPT en la creación de chatbots.
for pregunta in questions[-2:]:
result = qa({"question": pregunta})
print(pregunta)
print(result['answer'])
print('------')

Conclusiones
En este artículo hemos visto cómo crear un chatbot utilizando modelos de lenguaje GPT para que responda a preguntas sobre documentos privados.
Asimismo, hemos visto en qué consiste la técnica Retrieval Augmented Generation y cada una de sus fases desde la ingesta hasta la generación de respuestas con memoria.
En nuestro ejemplo hemos utilizado un documento pdf como base de conocimiento para el Chatbot y se le han proporcionado instrucciones para evitar las alucinaciones.
Por supuesto, es un modelo muy sencillo que sirve como base para comprender el funcionamiento general de una aplicación chatbot y que no está listo para su puesta en producción. De hecho, no es un chatbot totalmente privado puesto que utiliza APIs de terceros y envía información de los documentos a esas APIs.
Como hemos comentado en la introducción, cada una de las fases se pueden variar según las necesidades concretas, en este sentido, la privacidad se garantizaría utilizando modelos Open Source on-premise, también se puede mejorar utilizando otros tipos de fuentes de conocimiento como páginas web.
De todo esto hablaremos en otros artículos.
Foto de Google DeepMind: https://www.pexels.com/es-es/foto/abstracto-tecnologia-investigacion-aprendizaje-17483874/, resto de imágenes de producción propia

Deja un comentario